kakao/khaiii
Kakao Hangul Analyzer III. Contribute to kakao/khaiii development by creating an account on GitHub.
github.com
이번에 처음으로 공부해보면서 기본적인 모듈화와 함께 대형 프로젝트를 제대로 뜯어보기로 했다.
목표는 khaiii를 열심히 씹듣맛즐해보고
모두의 말뭉치 형태 분석 말뭉치를 기반으로, colab + pytorch_lightning으로 구현해보는 것.
된다면, cmake 같은 부분도 고쳐 import만을 통해 huggingface transformer와 같은 구조로 사용할 수 있도록 만들어보려 한다.
일단, 전체가 매우 방대하기 때문에 한 번 주요 구조를 클래스다이어그램으로 슬쩍 나타내어보았다.
정식 논문/퍼블리쉬 프로젝트용으로 그린 게 아니라 화살표/변수/파라미터 등의 표기에는 임의가 있다.
어차피 나만 보니까
모델 소스는 최근 추가된 python 모델을 기준으로 했다.
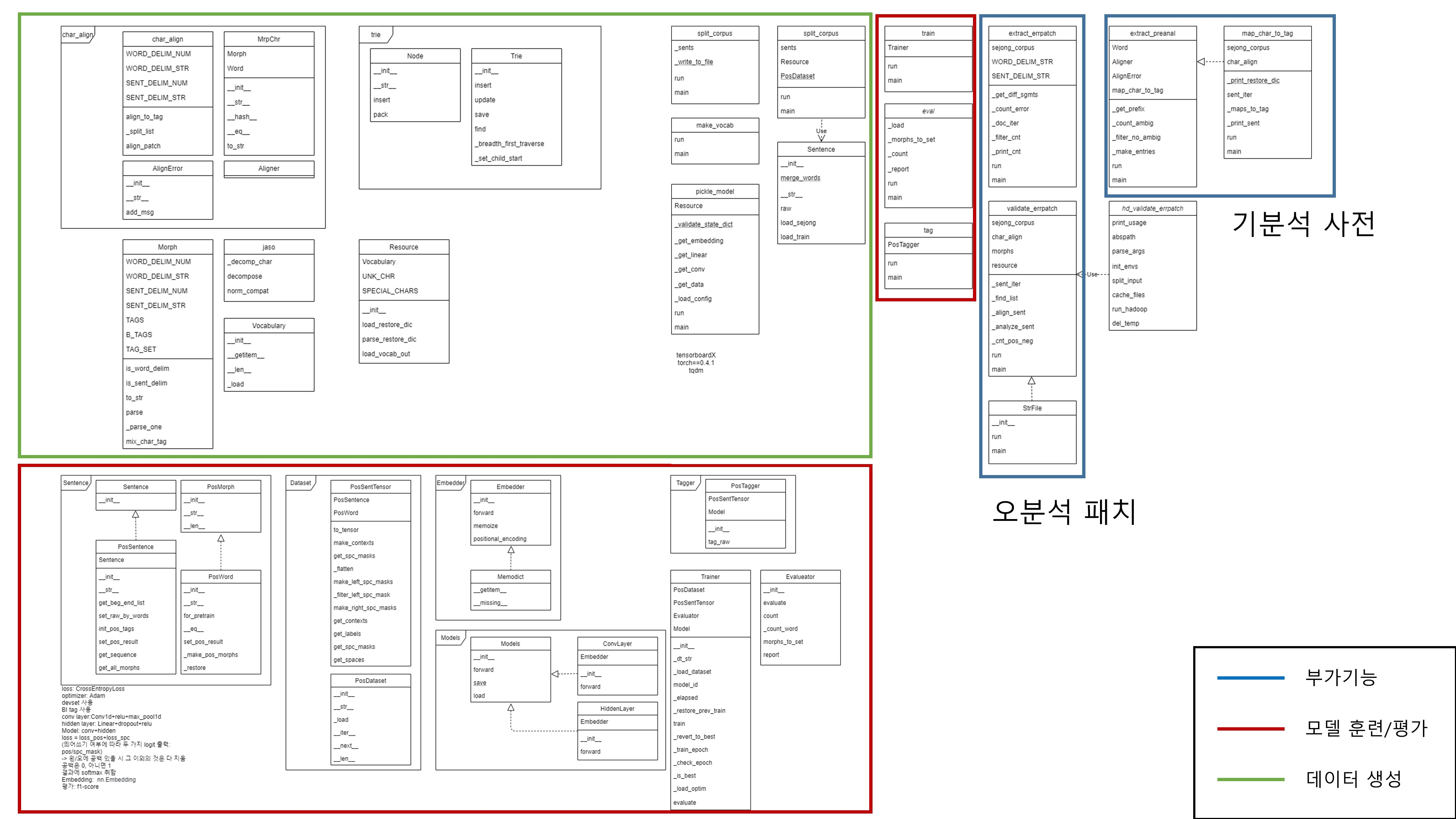
khaiii = 기분석 사전 + CNN으로 이루어진 모델을 이용한 tokenizer + 오분석 패치 라고 볼 수 있다.
C++로 개발되었으며, 그래서 실행 시 cmake가 필요하다고 한다.
실행 시에는 python 3가 필요하기 때문이다.
어쨌든, 이런 이유로 빌드할 때는 makefile을 이용해서 make all -> make resource -> make install 의 과정으로 사용한다.
코퍼스는 세종 코퍼스를 자체적으로 오류 수정하여 사용한다.
이름이 문종 코퍼스이던데, 재밌는 작명법인 거 같다.
전체를 크게 코퍼스/훈련/그 외(기분석 사전/오분석 패치) 로 나누었다.

코퍼스를 다루는 부분의 python 버전 차트이다. main에 해당하는 부분과 resource 생성에 해당하는 부분으로 분류하였다. 위치 차이
rsc에서는 makefile을 이용하여 char 단위의 데이터 파일을 생성한다.
compile_model에서는 resource의 객체와 함수를 이용하여 embed/conv/cnv2hdn/hdn2tag 네 가지의 데이터 파일을 생성한다. conv 파일은 레이어의 개수에 따라 더 생성한다.
compile_restore에서는 TAG_SET과 resource에서의 vocab 파일 읽는 함수(load_vocab_out)와 restore_dic을 불러오는 함수(parse_restore_dic)를 이용하여 원형복원 사전을 생성, 출력 태그 사전(vocab.out)을 수정한다.
데이터 생성에 관여하는 순서로 따지면,
make_vocab(vocab.in/vocab.out 생성) -> vocabulary -> morph, resource -> char_align
코퍼스를 쪼개는 순서로 따지면,
jaso < vocabulary < morph < char_align < resource
이렇다.
이렇게 생성된 다양한 사전들은 munjong 코퍼스에서 만들어진 Sentence, Word 객체와 함께 모델 훈련에 사용된다.
그렇다면, 훈련부는 어떻게 구성되어 있을까

역시 굉장히 복잡하다.
그러나, 메인 부분에 있는 함수는 대부분 훈련 라이브러리를 그대로 가져다 쓴다. 그래서 이에 대한 부분은 분석이 거의 필요하지 않았다.
dev/train/test 데이터셋은 train/dataset 파일에서
훈련하는 부분의 주요 사항은 이 정도로 표시해둘 수 있을 것 같다.
devset 사용
BI tag 사용
Embedding: nn.Embedding
loss: CrossEntropyLoss
optimizer: Adam
conv layer:Conv1d+relu+max_pool1d
hidden layer: Linear+dropout+relu
Model: conv+hidden
loss = loss_pos+loss_spc
(띄어쓰기 여부에 따라 두 가지 logit 출력: pos/spc_mask)
-> 왼/오에 공백 있을 시 그 이외의 것은 다 지움
이 때 공백은 0, 아니면 1
tagger에서는 결과에 softmax 취함
평가: f1-score
절차적으로 보면, 훈련은 이런 순서로 진행됨을 확인할 수 있다.
sentence(공백 masked 음절 단위로 쪼개진 문장) -> dataset(음절 to tensor) -> trainer -> evaluator -> tagger
embedder -> models ->
또한, 이와 함께 같이 사용하는 기술이 있다. 기분석 사전과 오분석 패치의 활용이다.

처음에 Makefile을 이용하여 다른 사전을 생성할 때, 함께 생성한다. compile_errpatch에서 오분석 패치된 엔트리들은 중복이 되지 않게 파일에 저장되며, compile_preanal에서 기분석 사전의 라인을 파싱하고, 이를 저장한다.
기분석 사전과 오분석 패치에는 TRIE 알고리즘이 사용된다.
TRIE는 그래프 알고리즘으로, 라인을 파싱하는 데에 쓰인다. 여기서 설명하긴 길 거 같다
두 기능은 서로 플로우가 매우 유사하다.
원형 분석 사전 -> 음절/형태소 분석 결과 정렬 -> 출력 태그 결정/번호 매핑 -> TRIE 저장
그래서 구현을 하려면, 다음의 순서로 하고자 한다.
데이터 -> 모델 -> 오분석 패치/기분석 사전
make_vocab(vocab.in/vocab.out 생성) -> vocabulary -> morph, resource
->sentence(공백 masked 음절 단위로 쪼개진 문장) -> dataset(음절 to tensor) -> embedder -> models -> trainer -> evaluator -> tagger
-> char_align -> trie
의 순서이다.
....음, 하고 나면 실력이 많이 늘 것 같다.